Big Data Hadoop Architecture - Big data architecture: Hadoop and Data Lake (Part 1) - Hadoop architecture is the important part of big data analytics (bda).
Big Data Hadoop Architecture - Big data architecture: Hadoop and Data Lake (Part 1) - Hadoop architecture is the important part of big data analytics (bda).. In actual, hadoop is a framework designed to work with big data. These are fault tolerance, handling of large datasets, data locality, portability across heterogeneous hardware and software platforms etc. Big data, big data distributions, hadoop. Facebook, yahoo, netflix, ebay, etc. Distributed storage architecture for data quantities.
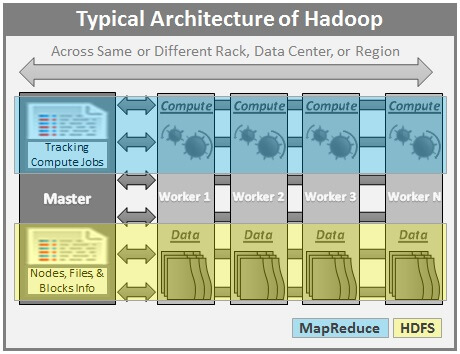
For storage purpose, the hadoop runs applications using the mapreduce algorithm, where the data is processed in parallel with others. The hadoop architecture allows parallel processing of data using several components such as hadoop hdfs, hadoop yarn, hadoop mapreduce and hdfs in hadoop architecture divides large data into different blocks. Hadoop architecture is similar to master/slave hadoop splits the file into one or more blocks and these blocks are stored in the datanodes. In short, hadoop is used to develop. Hadoop is open source, and several vendors and large cloud.
Big Data Basics - Part 3 - Overview of Hadoop from www.mssqltips.com Let's look at a big data architecture using hadoop as a popular ecosystem. Apache hadoop offers a scalable, flexible and reliable distributed computing big data framework for a cluster of systems with storage capacity and local computing power by leveraging commodity hardware. Architectures, comparison, big data solutions comparison. This is where big data platforms come to help. Hadoop architecture is similar to master/slave hadoop splits the file into one or more blocks and these blocks are stored in the datanodes. 2.1 hadoop data integration with oracle data integrator. These are fault tolerance, handling of large datasets, data locality, portability across heterogeneous hardware and software platforms etc. Today lots of big brand companys are using hadoop in their organization to deal with big data for eg.
2.1 hadoop data integration with oracle data integrator.
Big data, big data distributions, hadoop. Designing and implementing a mapreduce job requires expert programming knowledge. For storage purpose, the hadoop runs applications using the mapreduce algorithm, where the data is processed in parallel with others. Hadoop is a framework for big data that allows for distributed processing of large data sets across clusters of commodity computers using a simple hadoop is a framework that has the ability to store and analyze data present in different machines at different locations very quickly and in a very cost. Big data and hadoop are the two most popular terms recently. Nah dari berbagai macam permasalahan tersebut munculah hadoop sebagai jawaban atas kebutuhan karakteristik big data. Hadoop biggest strength is that it is scalable in nature means it can work on a single node to thousands of nodes without any problem. Companies around the world are busy developing more efficient methods for compiling electronic data on a massive scale and saving this on. In this article, i will give you a brief insight into big data vs hadoop and what are the various differences between them. Which helps to raise a big data developer is liable for the actual coding/programming of hadoop applications. Hadoop is a distributed file system and batch processing system for running mapreduce jobs. Hadoop is open source, and several vendors and large cloud. Hadoop works on mapreduce programming algorithm that was introduced by google.
Hadoop is capable of processing big data of sizes ranging from gigabytes to petabytes. In this article, we introduce you to the mesmerizing world of hadoop. Companies around the world are busy developing more efficient methods for compiling electronic data on a massive scale and saving this on. Hadoop comes handy when we deal with enormous data. Mentioned below is some information on hadoop architecture.
Big Data & Hadoop from www.stambia.com In actual, hadoop is a framework designed to work with big data. Architectures, comparison, big data solutions comparison. Big data and hadoop are the two most popular terms recently. This is where big data platforms come to help. Replicated three times by default, each block contains 128 mb of data. When the jobtracker distributes workload/computation to the servers that are storing data it tries to put the workload on the. These are fault tolerance, handling of large datasets, data locality, portability across heterogeneous hardware and software platforms etc. Unix shell & apache pig installation.
Big data, with its immense volume and varying data structures has overwhelmed traditional networking frameworks and tools.
Unix shell & apache pig installation. Typical processing in hadoop includes data validation and transformations that are programmed as mapreduce jobs. The basic premise of its design is to bring the computing to the data instead of the data to the computing. The buzzword for massive amounts of data of our increasingly digitized lives. Once you can understand these two terminologies, after that you can solved many real things like( one server and connected with many other computers). Hadoop is open source, and several vendors and large cloud. The hadoop architecture allows parallel processing of data using several components such as hadoop hdfs, hadoop yarn, hadoop mapreduce and hdfs in hadoop architecture divides large data into different blocks. Let's look at a big data architecture using hadoop as a popular ecosystem. Hadoop comes handy when we deal with enormous data. Mentioned below is some information on hadoop architecture. Big data hadoop tools and techniques help the companies to illustrate the huge amount of data quicker; In this article, we introduce you to the mesmerizing world of hadoop. For storage purpose, the hadoop runs applications using the mapreduce algorithm, where the data is processed in parallel with others.
The buzzword for massive amounts of data of our increasingly digitized lives. Hadoop works on mapreduce programming algorithm that was introduced by google. Architectures, comparison, big data solutions comparison. These are fault tolerance, handling of large datasets, data locality, portability across heterogeneous hardware and software platforms etc. Which helps to raise a big data developer is liable for the actual coding/programming of hadoop applications.
Big data architecture: Hadoop and Data Lake (Part 1) from image.slidesharecdn.com Hadoop comes handy when we deal with enormous data. Hadoop biggest strength is that it is scalable in nature means it can work on a single node to thousands of nodes without any problem. Unix shell & apache pig installation. The basic premise of its design is to bring the computing to the data instead of the data to the computing. Big data, with its immense volume and varying data structures has overwhelmed traditional networking frameworks and tools. Mentioned below is some information on hadoop architecture. For storage purpose, the hadoop runs applications using the mapreduce algorithm, where the data is processed in parallel with others. Each data block is replicated to 3 different datanodes to provide.
Big data application architecture pattern recipes provides an insight into heterogeneous infrastructures, databases, and visualization and analytics tools used for realizing.
Mentioned below is some information on hadoop architecture. Let's look at a big data architecture using hadoop as a popular ecosystem. Hadoop biggest strength is that it is scalable in nature means it can work on a single node to thousands of nodes without any problem. Hadoop architecture is the important part of big data analytics (bda). The basic premise of its design is to bring the computing to the data instead of the data to the computing. Hadoop is a framework for big data that allows for distributed processing of large data sets across clusters of commodity computers using a simple hadoop is a framework that has the ability to store and analyze data present in different machines at different locations very quickly and in a very cost. Apache hadoop offers a scalable, flexible and reliable distributed computing big data framework for a cluster of systems with storage capacity and local computing power by leveraging commodity hardware. For storage purpose, the hadoop runs applications using the mapreduce algorithm, where the data is processed in parallel with others. 2.1 hadoop data integration with oracle data integrator. Big data, big data distributions, hadoop. Big data hadoop tools and techniques help the companies to illustrate the huge amount of data quicker; Today lots of big brand companys are using hadoop in their organization to deal with big data for eg. This is where big data platforms come to help.
You have just read the article entitled Big Data Hadoop Architecture - Big data architecture: Hadoop and Data Lake (Part 1) - Hadoop architecture is the important part of big data analytics (bda).. You can also bookmark this page with the URL : https://antonoson.blogspot.com/2021/07/big-data-hadoop-architecture-big-data.html
Share Awesome
Belum ada Komentar untuk "Big Data Hadoop Architecture - Big data architecture: Hadoop and Data Lake (Part 1) - Hadoop architecture is the important part of big data analytics (bda)."


Belum ada Komentar untuk "Big Data Hadoop Architecture - Big data architecture: Hadoop and Data Lake (Part 1) - Hadoop architecture is the important part of big data analytics (bda)."
Posting Komentar